Evaluation protocol
The methodology described hereinafter is implemented in evaluate.py (Evaluate).
Thanks to the initialization protocol, the performance of a policy does not depend of an arbitrarily chosen initial distance between the source and the agent, nor is affected by artificial finite-size effects.
Policy evaluation is performed by generating a large number of episodes and computing the resulting distribution of arrival times \(T\), denoted here \(f(T)\), and defined such that its norm is the probability of (ever) finding the source (which may not be equal to one), that is,
Other moments of the distribution are computed after renormalization as usual, for example:
with \(\tilde{f}(T) = f(T) / \sum_T f(T)\).
The convergence of \(f(T)\) with the number of episodes can be vastly improved by realizing that \(p({\bf x})\),
interpreted as the agent’s belief in the context of decision-making, is also the true (in the Bayesian sense)
probability distribution of sources that could have generated the sequence of observations.
In this probabilistic approach, each episode can be continued until the probability of having found the source is equal
to one (within numerical accuracy STOP_p) or until the agent is stuck in an infinite loop, and hits are drawn
at each step according to the distribution:
such that episodes can be generated independently of the true source location \({\bf x}^s\).
A video illustrating how the search proceeds in this framework is shown below. It can be visualized with
visualize.py (Visualize) using DRAW_SOURCE = False.
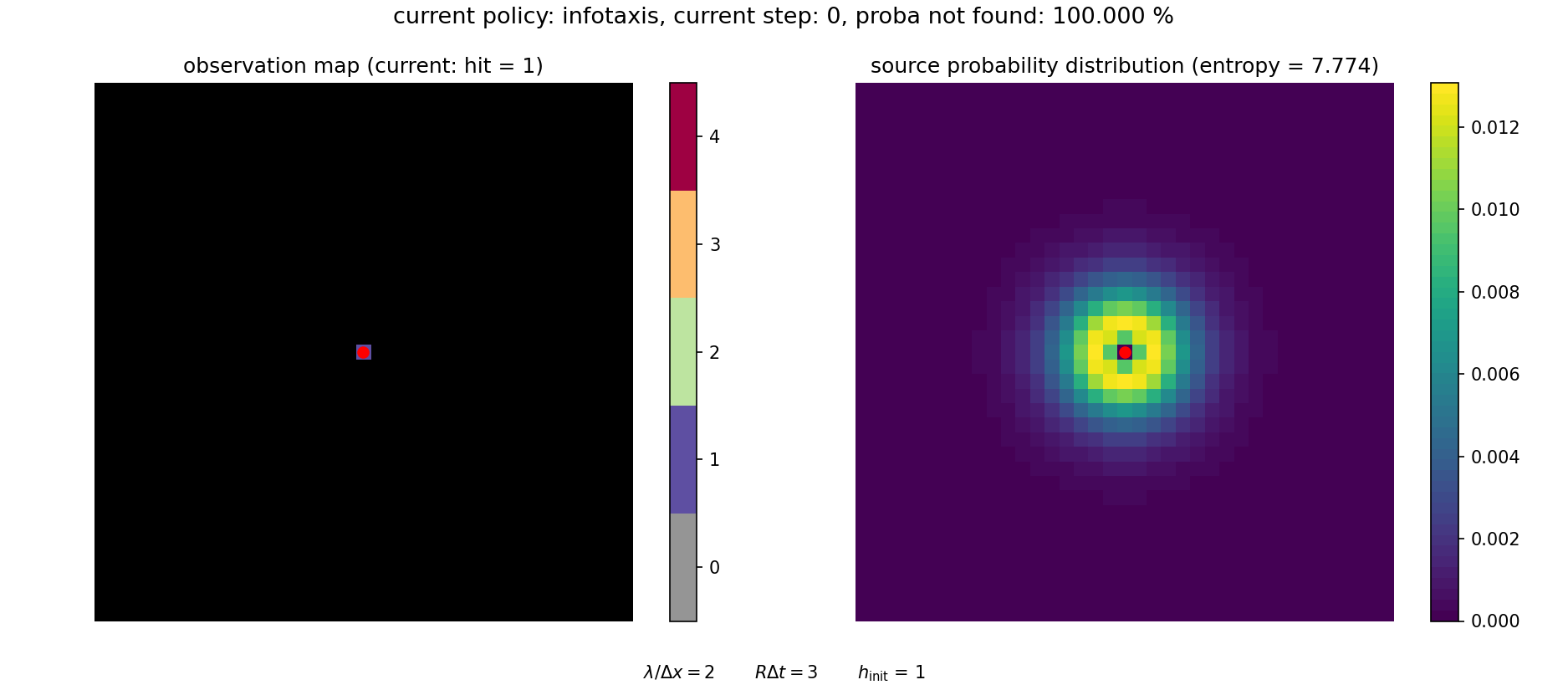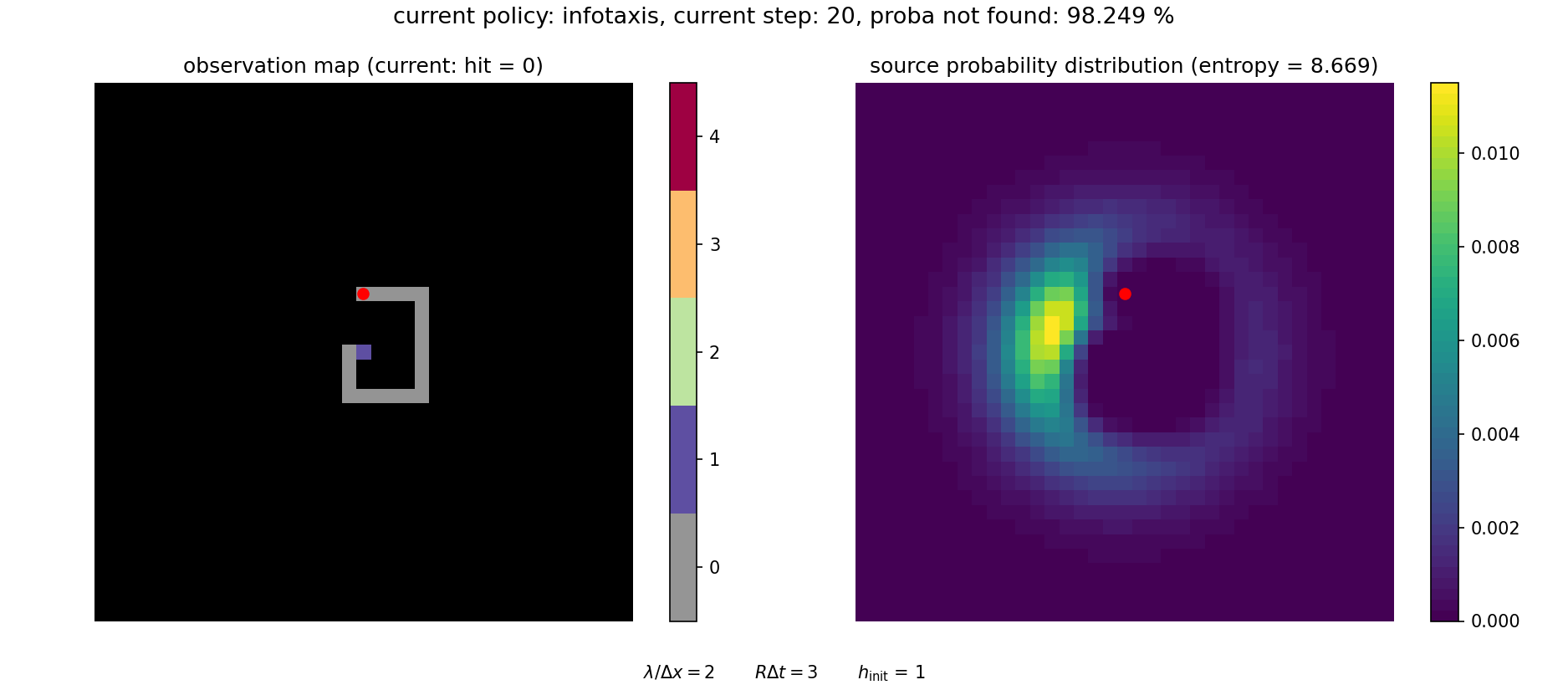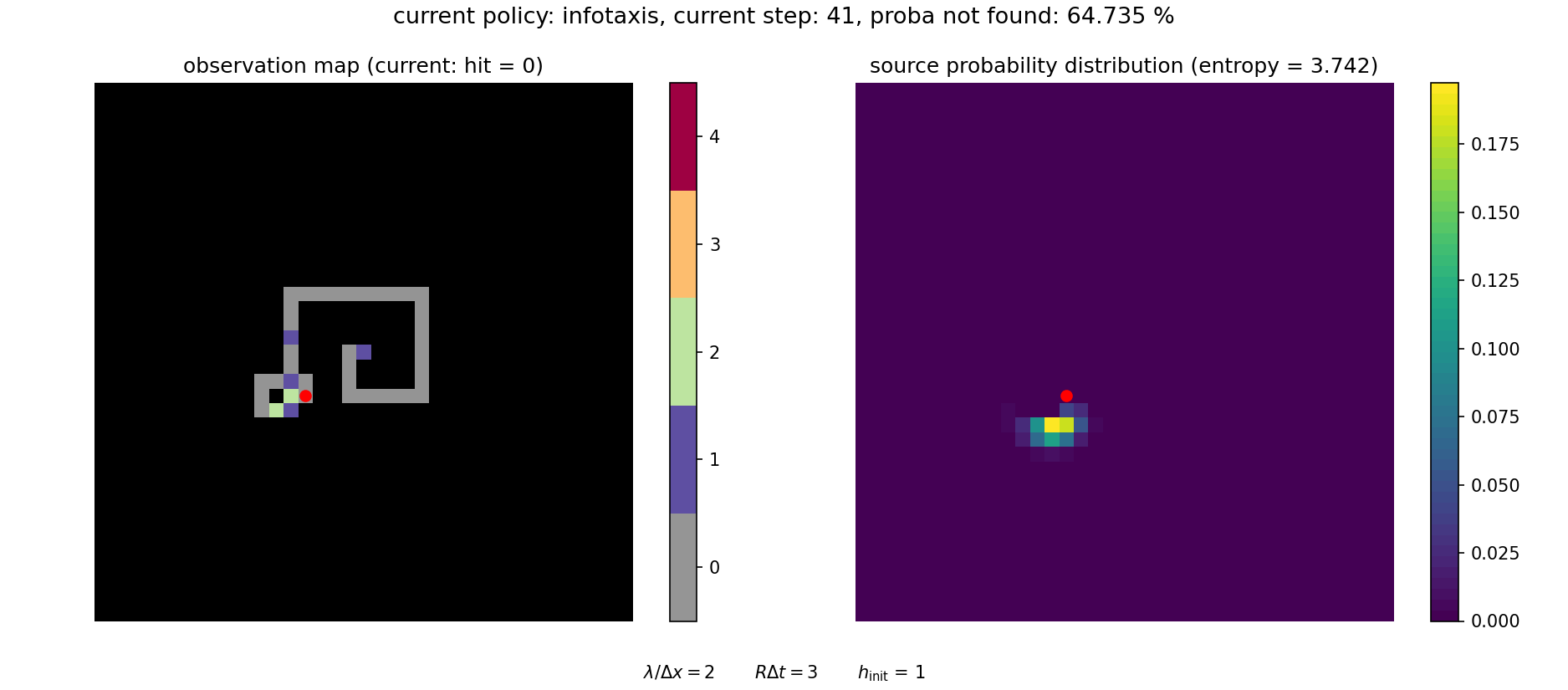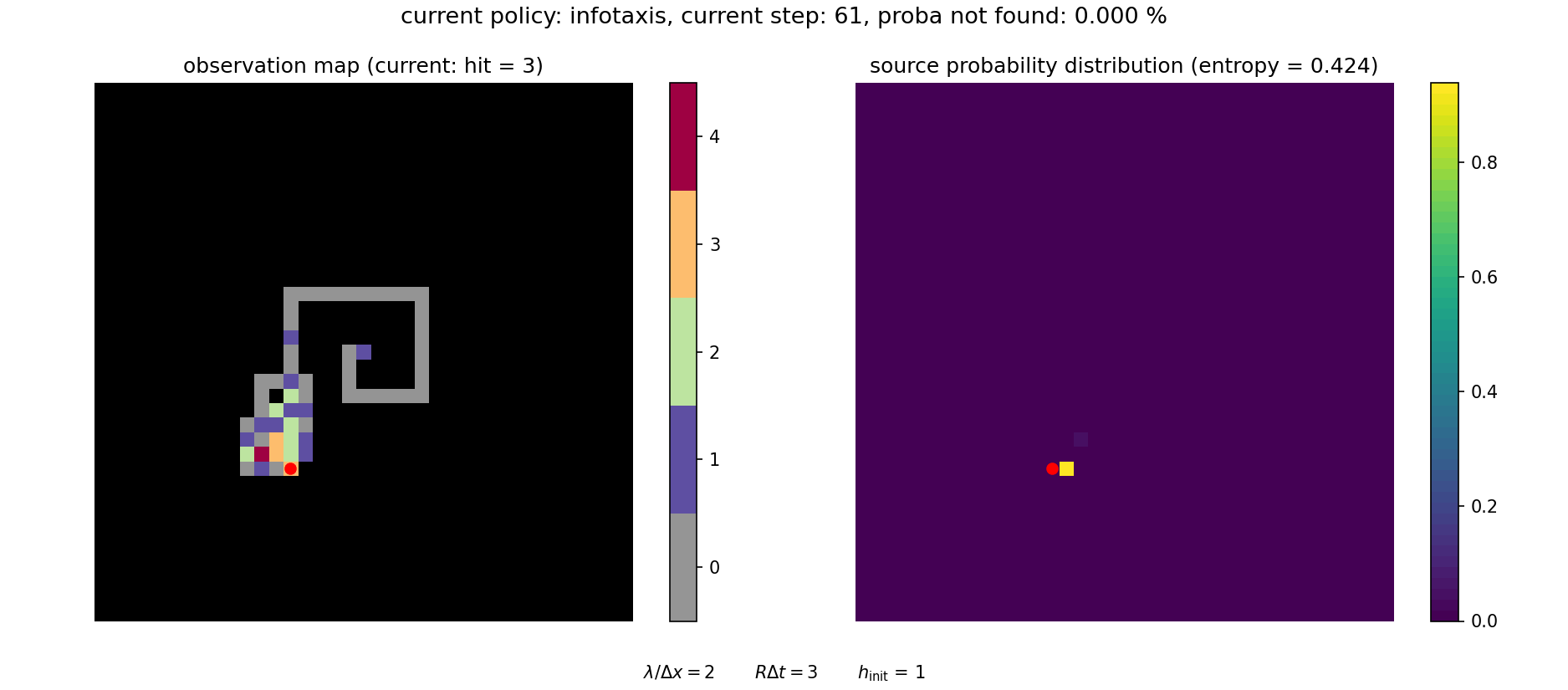
The search can be continued until the source is (almost) surely found.
This approach is particularly advantageous to sample rare events (such as failing to find the source) and more generally to sample heavy-tailed distributions (as is \(f(T)\)). The pseudo-code for computing the distribution of arrival times is given in below.

Pseudo-code for the policy evaluation algorithm.